07、Kubernetes - 实战:Deployment 的 yaml 描述、使用 kubectl 创建 deployment、通过 labels 标签筛选应用
Deployment顾名思义,它是专门用来部署应用程序的,能够让应用永不宕机,多用来发布无状态的应用。
Pod 里面的 restartPolicy只能保证容器正常工作。如果容器之外的 Pod 出错了该怎么办呢?比如说,有人不小心用 kubectl delete 误删了 Pod,或者 Pod 运行的节点发生了断电故障,那么 Pod 就会在集群里彻底消失,对容器的控制也就无从谈起了。
在线业务远不是单纯启动一个 Pod 这么简单,还有多实例、高可用、版本更新等许多复杂的操作。比如最简单的多实例需求,为了提高系统的服务能力,应对突发的流量和压力,我们需要创建多个应用的副本,还要即时监控它们的状态。如果还是只使用 Pod,那就会又走回手工管理的老路,没有利用好 Kubernetes 自动化运维的优势。
既然Pod 管理不了自己,那么我们就再创建一个新的对象,由它来管理 Pod,采用和 Job/CronJob 一样的形式——“对象套对象”。这个用来管理 Pod,实现在线业务应用的新 API对象,就是 Deployment。
1. yaml 描述
用命令kubectl api-resources 来看看 Deployment 的基本信息,
wohu@dev:~/k8s$ kubectl api-resources | grep deployment
NAME SHORTNAMES APIVERSION NAMESPACED KIND
deployments deploy apps/v1 true Deployment
从它的输出信息里可以知道,Deployment 的简称是 deploy,它的 apiVersion 是 apps/v1,kind 是 Deployment。
创建Deployment 样板的方式
export out="--dry-run=client -o yaml"
kubectl create deploy ngx-dep --image=nginx:alpine $out
得到的Deployment 样板大概是下面的这个样子:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ngx-dep
name: ngx-dep
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
containers:
- image: nginx:alpine
name: nginx
先看replicas 字段。就是“副本数量”的意思,也就是说,指定要在 Kubernetes 集群里运行多少个 Pod 实例。
Deployment 对象就可以扮演运维监控人员的角色,自动地在集群里调整 Pod 的数量。
比如,Deployment 对象刚创建出来的时候,Pod 数量肯定是 0,那么它就会根据 YAML 文件里的 Pod 模板,逐个创建出要求数量的 Pod。
接下来Kubernetes 还会持续地监控 Pod 的运行状态,万一有 Pod 发生意外消失了,数量不满足“期望状态”,它就会通过 apiserver、scheduler 等核心组件去选择新的节点,创建出新的 Pod,直至数量与“期望状态”一致。
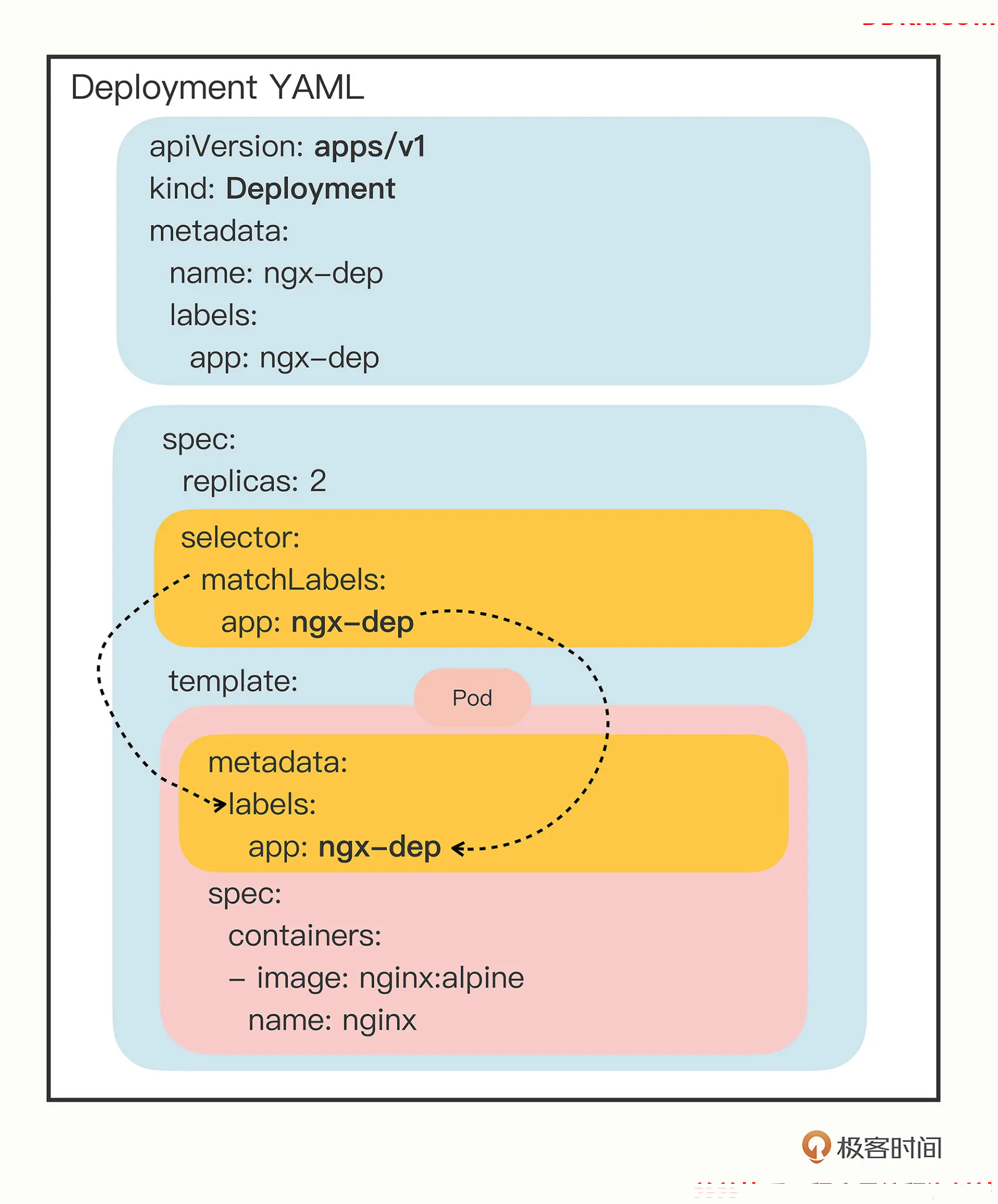
下面我们再来看另一个关键字段 selector,它的作用是“筛选”出要被 Deployment 管理的 Pod 对象,下属字段 matchLabels定义了 Pod 对象应该携带的 label,它必须和 template里 Pod 定义的 labels完全相同,否则 Deployment 就会找不到要控制的 Pod 对象,apiserver 也会告诉你 YAML 格式校验错误无法创建。
这个selector 字段的用法初看起来好像是有点多余,为了保证 Deployment 成功创建,我们必须在 YAML 里把 label 重复写两次:
- 一次是在 selector.matchLabels,
- 另一次是在 template.matadata。
像在这里,你就要在这两个地方连续写 app: ngx-dep :
...
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
...
你也许会产生疑问:为什么要这么麻烦?为什么不能像 Job 对象一样,直接用template里定义好的 Pod 就行了呢?
这是因为在线业务和离线业务的应用场景差异很大。离线业务中的 Pod 基本上是一次性的,只与这个业务有关,紧紧地绑定在 Job 对象里,一般不会被其他对象所使用。
而在线业务就要复杂得多了,因为 Pod 永远在线,除了要在 Deployment 里部署运行,还可能会被其他的 API 对象引用来管理,比如负责负载均衡的 Service 对象。
所以Deployment 和 Pod 实际上是一种松散的组合关系,Deployment 实际上并不“持有”Pod 对象,它只是帮助 Pod 对象能够有足够的副本数量运行,仅此而已。如果像 Job 那样,把 Pod 在模板里“写死”,那么其他的对象再想要去管理这些 Pod 就无能为力了。
好明白了这一点,那我们该用什么方式来描述 Deployment 和 Pod 的组合关系呢?
Kubernetes 采用的是这种“贴标签”的方式,通过在 API 对象的 metadata元信息里加各种标签(labels),我们就可以使用类似关系数据库里查询语句的方式,筛选出具有特定标识的那些对象。通过标签这种设计,Kubernetes 就解除了 Deployment 和模板里 Pod 的强绑定,把组合关系变成了“弱引用”。
画了一张图,用不同的颜色来区分 Deployment YAML 里的字段,并且用虚线特别标记了 matchLabels 和 labels 之间的联系,希望能够帮助你理解 Deployment 与被它管理的 Pod 的组合关系。
2. 使用 kubectl 操作 Deployment
这里我们使用 rabbitmq 镜像来创建一个 deploy
# 创建 deployment 对象
kubectl apply -f deploy.yml
# 查看状态
kubectl get deploy
查看结果:
wohu@dev:~/k8s$ kubectl apply -f mq-deploy.yml
deployment.apps/mq-dep created
wohu@dev:~/k8s$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
mq-dep 2/2 2 2 37s
wohu@dev:~/k8s$
- READY 表示运行的 Pod 数量,前面的数字是当前数量,后面的数字是期望数量,所以“2/2”的意思就是要求有两个 Pod 运行,现在已经启动了两个 Pod。
- UP-TO-DATE 指的是当前已经更新到最新状态的 Pod 数量。因为如果要部署的 Pod数量很多或者 Pod 启动比较慢,Deployment 完全生效需要一个过程,UP-TO-DATE 就表示现在有多少个 Pod 已经完成了部署,达成了模板里的“期望状态”。
- AVAILABLE 要比 READY、UP-TO-DATE 更进一步,不仅要求已经运行,还必须是健康状态,能够正常对外提供服务,它才是我们最关心的 Deployment 指标。
- 最后一个 AGE 就简单了,表示 Deployment 从创建到现在所经过的时间,也就是运行的时间。
因为Deployment 管理的是 Pod,我们最终用的也是 Pod,所以还需要用 kubectl get pod 命令来看看 Pod 的状态:

从截图里你可以看到,被 Deployment 管理的 Pod 自动带上了名字,命名的规则是 Deployment 的名字加上两串随机数(其实是 Pod 模板的 Hash 值)。
来尝试一下吧,看看 Deployment 部署的应用真的可以做到“永不宕机”?让我们用 kubectl delete 删除一个 Pod,模拟一下 Pod 发生故障的情景:
kubectl delete pod mq-dep-75f9d977f7-brsqj
然后再查看 Pod 的状态:

可以发现被删除的 Pod 确实是消失了,但 Kubernetes 在 Deployment 的管理之下,很快又创建出了一个新的 Pod,保证了应用实例的数量始终是我们在 YAML 里定义的数量。这就证明,Deployment 确实实现了它预定的目标,能够让应用“永远在线”“永不宕机”。
kubectl scale 是专门用于实现“扩容”和“缩容”的命令,只要用参数 --replicas 指定需要的副本数量,Kubernetes 就会自动增加或者删除 Pod,让最终的 Pod 数量达到“期望状态”。
比如下面的这条命令,就把 mq 应用扩容到了 5 个:
kubectl scale --replicas=5 deploy mq-dep
但要注意, kubectl scale 是命令式操作,扩容和缩容只是临时的措施,如果应用需要长时间保持一个确定的 Pod 数量,最好还是编辑 Deployment 的 YAML 文件,改动 replicas,再以声明式的 kubectl apply 修改对象的状态。
3. labels 字段
之前我们通过 labels 为对象“贴”了各种“标签”,在使用 kubectl get 命令的时候,加上参数 -l,使用 ==、!=、in、notin 的表达式,就能够很容易地用“标签”筛选、过滤出所要查找的对象,效果和 Deployment 里的 selector 字段是一样的。
看两个例子,第一条命令找出 app 标签是 mq 的所有 Pod,第二条命令找出 app 标签是 mq、rabbitmq、mq-dep 的所有 Pod:
kubectl get pod -l app=mq
kubectl get pod -l 'app in (mq, rabbitmq, mq-dep)'
学了Deployment 这个 API 对象,我们今后就不应该再使用“裸 Pod”了。即使我们只运行一个 Pod,也要以 Deployment 的方式来创建它,虽然它的 replicas 字段值是 1,但 Deployment 会保证应用永远在线。
另外,作为 Kubernetes 里最常用的对象,Deployment 的本事还不止这些,它还支持滚动更新、版本回退,自动伸缩等高级功能。
4. 补充
Deployment 实际上并不是直接管理 Pod,而是用了另外一个对象 ReplicaSet,它才是维护 Pod 多个副本的真正控制器。
其实Job/CronJob 里面也是用 selector 字段来组合 Pod 对象的,但一般不用显示写出,Kubernetes 会自动生成一个全局唯一的 label,实质还是强绑定关系。
标签名由前缀、名称组成。前缀必须符合域名规范,最多 253 个字符;名称允许有字母、数字、-、_、.、最多 63 个字符。
Deployment 里 metadata 的 labels 与 spec 的 labels 虽然通常是一样的,但它们没有任何关系,spec 的 labels 只管理 Pod。
1、 如果把Deployment里的replicas字段设置成0会有什么效果?有什么意义呢?;
答复:
$ kubectl get po -n nginx-deploy
No resources found in default namespace.
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/0 0 0
意义:关闭服务的同时,又可以保留服务的配置,下次想要重新部署的时候只需要修改 deployment 就可以快速上线。
1、 你觉得Deployment能够应用在哪些场景里?有没有什么缺点或者不足呢?;
答复: 使用场景:用在部署无状态服务,部署升级,对服务的扩缩容;
不足:Deployment 把所有 pod 都认为是一样的服务,前后没有顺序,没有依赖关系,同时认为所有部署节点也是一样的,不会做特殊处理等。deploy 是只能用在应用是无状态的场景下,对于有状态的应用它就无能为力了,需要使用其他的 api。
对这句话有个疑问,“kubectl scale 是命令式操作,扩容和缩容只是临时的措施,如果应用需要长时间保持一个确定的 Pod 数量,最好还是编辑 Deployment 的 YAML 文件” 我刚实验通过kubectl scale去扩容pod数量,然后通过kubectl delete去删除一个pod,立马又会新生成一个pod,所以通过kubectl scale也是能保持一个确定的pod数量的吧?通过yaml文件去改变副本的好处准确来说应该是让整个生产环境里只有一份配置的描述,避免当kubectl scale执行后,实际deployment规格与yaml文件里不一致,避免让运维引发混淆
作者回复: Pod 是由 Deployment 模板创建出来的,它受 Deployment 管控,单独创建 Pod 无法纳入 Deployment 的管理,因为 Kubernetes 就是这么规定的运行机制。
deployment 的使用场景,是无状态的应用,每次 deloy 启动 pod 会在固定名称后面加入随机字符串,对于有状态的服务,需要使用 k8s 其他组件。