01、Sharding-JDBC 实战;介绍和基本原理
接下来的几篇文章将通过理论和代码操作实例的方式快速入门shadingjdbc(5.0版本)。
简单介绍
shardingjdbc是一个用来分库分表的框架是shadingsphere 的一个子项目。
shadingsphere 截止目前包含了3个产品,JDBC,Proxy 和 Sidecar。shadingsphere在 2020
年已经是apache顶级项目。
官网地址: ShardingSphere
shardingjdbc 主要的功能是针对支持jdbc 规范的关系型数据库做分库分表等操作。
支持的数据库有 Mysql,openGauss,postgreSQL,SQLServer,Oracle,SQL92
为什么要分库分表
在实际开发场景中,会遇到有些数据表数据量比较大的场景,而mysql对数据量的承受能力是有限的,比如当单表数据量超过一定的数量,单表通过索引查询会遇到一个性能瓶颈,查询会比较的慢。那么就需要考虑分表查询和存储。随着业务的发展和并发量的增加,即使分了表,单台数据库的性能压力还会比较大,主要体现在CPU,IO,内存等压力并没有分解,那么需要对数据进行分库存储分担查询压力。
一句话:分库分表解决了数据库表存储容量和单台数据库压力的问题。
怎么分库分表
垂直拆分
将一个表的不同字段放到不同的表中。比较一个用户信息表,有一些基本信息比如用户名 姓名 手机号等 还有一些比如个人等级,个人积分等,将这些不同的类似的信息放到不同的2个表中,达到垂直拆分的效果。此种方式不再赘述,这里详细说明水平拆分的方式。
水平拆分
水平拆分需要将一个表中的数据分散到多个表或库中。
常见的拆分方式有
根据取模的方式拆分
在不分库的时候有一个order 表。目前想将数据分散到10个表中。对应t_order_0,t_order_1,t_order_2,t_order_3.... t_order_9 ,那么需要一定的规则来定义数据应该进入到那个表中,比如oder 上有一个用户id,那么对用户id 对 10 取模来决定数据应该落到那个表中;
举例:一条数据 用户id 为 1,那么 1 % 10 = 1 所以这条数据应该插入到order_1
根据日期拆分
如果业务中主要是根据时间范围做查询操作,比如 报表统计操作 等。那么可以将数据根据天,月,年 不同的维度进行存储。
一致性hash
一致性性hash算法通过hash环的方式,本质是hash后寻找下一个目标数据值。主要的优点是在增进新的库的时候对旧数据库中的迁移工作会比较的小。
基本原理
shadingjdbc 做了什么操作能够完成分库分表操作。对于数据库的操作基本包含2个操作,写操作和读操作。针对写操作来说要将数据写入对应的分表中,读操作要能够从分表中读取到对应的数据。
以订单表为例说明,假如订单表上有t_order 有10张表,同时订单表上有user_id 字段。
shadingjdbc 对我们写的查询大致做这几个步骤以实现分表逻辑;
sql 解析 ==> sql 路由 ==> sql 改写 ==> sql 执行 ==> 结果归并
举例说明:insert into t_oder(id,user_id,info) values(1,1,'xx');
sql解析:提取sql中的信息,比如那个表,那些字段,对应的值是什么。能够获取到要插入到 t_oder表中,并且数据上的user_id 是 1
sql路由:根据user_id 是1 ,就可以算出要插入到t_oder_1 这个表中
sql改写:这个sql 肯定不能发出啊,需要执行处理后的sql ,所以改写sql成
insert into t_oder_1(id,user_id,info) values(1,1,'xx');
sql执行:执行真实的sql
结果归并:如果是插入操作那可能不需要复杂的处理,而如果是查询操作,一个查询可能需要发送多条sql,将多个sql的结果都拿过来合并一个执行结果来返回给用户。
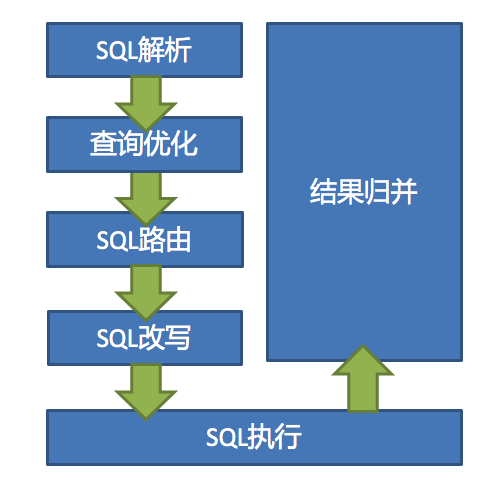
图片来自官网,具体可详细查看官网介绍 https://shardingsphere.apache.org/document/5.0.0/cn/reference/sharding/
基本概述说明
在分库分表中有需要的概念需要了解下。
- 逻辑表:一组分表的总称,比如t_oder_0 t_order_1 的逻辑表就是t_order ,写sql对应的是逻辑表写;
- 真实表: 顾名思义 真实存在的表,比如 t_order_0
- 绑定表: 具有相同的分片规则的表相互绑定互为绑定表;比如说 user 表和order 表都分了表,并且都是根据user_id 进行分表的,所以对于同一个用户的数据来说,落到两个表的后缀是一定并且确定的,那么在关联查询user 和order 的时候,不管拿到user 或order 的谁的分片信息,都就知道查那个表了,比如我查询条件里知道要查 user 表的user_id = 3 的时候,order的表也是知道的.
- 广播表:像广播一样,都能收到。每个表能接收到;
- 单表:不分表的表
- 数据节点:每个数据库的每个分真实表,就是一个数据节点。
- 分片键(需要配置):比如t_order 根据user_id 取模进行分片,那么user_id 就是分片键。
- 分片算法(需要定义): 通过配置分片算法,完成数据分发规则。内置了简单的通过Groovy 配置的简单分片算法,也可以通过自定义分片算法灵活完成需求;
- 分片策略: 包含分片键和分片算法
- 强制分片路由:可以通过Api的方式,让我们不根据配置而是编码的方式更加灵活的路由到指定的分片。
本教程使用版本和环境介绍
| JDK版本 | 1.8 |
| Mysql 版本 | 5.7 |
| spring boot 版本 | 2.6.2 |
| shardingjdbc版本 | 5.0.0 |