21、JVM 调优实战 - 每日请求上亿的电商系统,老年代的垃圾回收参数该如何优化?
1. 年轻代JVM优化回顾
在每日百万日活以及上亿请求量的电商系统的案例中,在大促期间的瞬时高峰下单场景下,JVM优化分析后,得出在大促高峰期,每秒每台机器会有300个下单请求。
进而推测出每秒钟会使用60MB的内存,根据这个背景推算出了一台4核8G的机器上,应该如何合理的给JVM各个区域分配内存。
进而可以保证每隔20多秒一次新生代GC后的100MB左右的存活对象,会进入200MB的Survivor区域内,一般不会因为Survivor塞不下或者是动态年龄判定规则让对象进入老年代中。
同时还根据 Minor GC的频率,合理降低了大龄对象进入老年代的年龄,尽快让一些长期存活的对象赶紧进入老年代,不要停留在新生代。如下图:
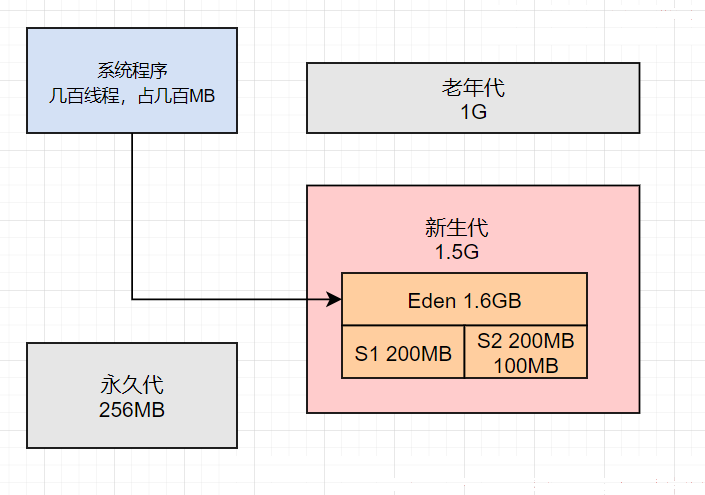
此时的JVM参数如下:
“-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=5 -XX:PertenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC”
2. 在案例背景下什么时候对象会进入老年代?
第一种情况,就是 “-XX:MaxTenuringThreshold=5” 这个参数会让在一两分钟内存连续躲过5次Minor GC的对象迅速进入老年代中。
这种对象一般就是一些 @Service、@Controller之类的注解标注的系统业务逻辑组件,这种对象实例一般全局就有一个实例就可以了,要一直使用的。
所以一般会长期被GC Roots引用,但这种对象一般不多,一个系统大概就几十MB这种对象。
所以此时类似这样的长期存活的对象就会进入老年代中,如下图:
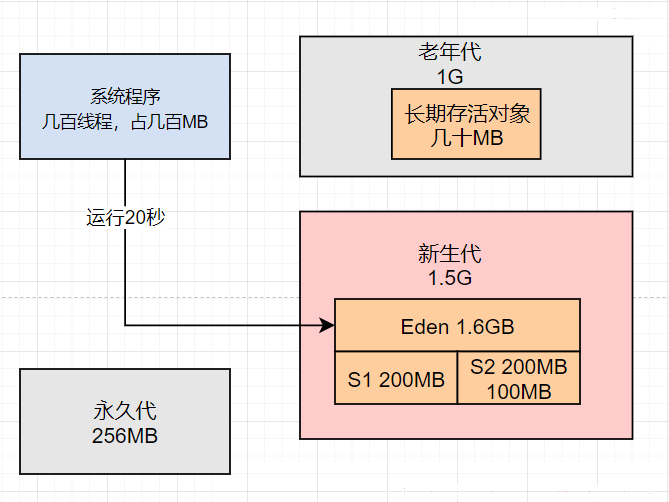
第二种情况是,按照JVM 的参数,如果分配一个超过1MB的大对象,比如一个大数组或大List之类的,就会直接进入老年代。
但这种大对象在案例里是没有的,可以忽略不记。
第三种情况就是,Minor GC过后可能存活的对象超过200MB放不下Survivor了,或者是一下子占到超过Survivor的50%,此时会有一些对象进入老年代中。
前面对新生代的JVM参数进行优化过,避免了这种情况,经过测算,这种概率应该是很低的。
3. 大促期间多久会触发一次Full GC?
Full GC的触发条件目前有以下4中:
1、 没有打开 “-XX:HandlePromotionFailure” 选项,结果老年代可用内存最多也就1G,新生代对象总大小最多可以有1.8G
这就会导致每次 Minort GC前一检查,都发现 “老年代可用内存” < “新生代总对象大小” ,这会导致每次Minort GC前都触发 Full GC。
不过在JDK1.6以后的版本废弃了这个参数,所以这个条件也就没有了。
2、 每次Minor GC之前,都检查一下 “老年代可用内存空间” < “历次Minor GC 后升入老年代的平均对象大小”
目前的案例中,要多次Minor GC之后才可能有一两次碰巧会有200MB对象升入老年代,所以这个条件触发的几率很小。
3、 可能某次Minor GC后要升入老年代的对象有几百MB,但是老年代可用空间不足了
4、 设置了 “-XX:CMSInitiatingOccupancyFaction” 参数,比如设定值为 92%,那么此时可能前面几个条件都没满足,但是刚好发现这个条件满足了,比如就是老年代空间使用超过 92%了,此时就会自行触发 Full GC。
在真正的系统运行期间,可能会慢慢的有对象进入老年代,但是因为新生代优化过了内存分配,所以对象进入老年代的速度是很慢的。
很可能在系统运行半小时~1小时之后,才会有接近1GB的对象进入老年代。当老年代被占满,就有可能满足上述 234中任何一个条件来触发 Full GC。
根据以上推论,按照大促开始10分钟就有50万订单来计算,假设1小时的时候就可能有两三百万订单了,而过了这个高峰期后,订单系统访问压力就很小了,那么GC的问题也就几乎不算什么了。
所以,经过新生代的优化,可以推算出,基本上大促高峰期内,可能1小时才1次Full GC,然后高峰期一过,随着订单系统慢慢运行,可能就需要几个小时才有一次 Full GC。
4. 老年代GC的时候会发生 “Concurrent Mode Failure”
假设订单系统运行1小时之后,老年代大概有900MB的对象,剩余可用空间仅仅只有100MB了,此时就会触发一次Full GC。
但是,在CMS进行垃圾回收的时候,尤其是并发清理期间,系统程序是可以并发运行的,所以此时老年代空闲空间仅剩100MB了。
然后此时系统程序还在不停地创建对象,万一这个时候系统触发了某个条件,比如说有200MB对象要进入老年代。
这个时候就会触发 “Concurrent Mode Failure” 问题,因为此时老年代没有足够内存来放这 200MB对象,就会导致立马进入 STW,然后切换 CMS为 Serial Old,直接禁止程序运行,然后单线程进行老年代垃圾回收,回收掉900MB对象过后,再让系统继续运行。
当然,上述的情况发生的概率是很小的。只是理论上有可能发生而已。所以,对于这种小概率事件而言,就没必要去调整参数了。
此时JVM参数如下:
“-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=5 -XX:PertenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFaction=92”
5. CMS垃圾回收之后进行内存碎片整理的频率应该多高?
在CMS完成Full GC之后,一般需要执行内存碎片的整理,可以设置多少次Full GC之后执行一次内存碎片整理。
但这里没必要修改这些参数,因为在大促高峰期,Full GC可能也就1小时执行一次,然后大促高峰期过去后,由于订单的锐减,可能几个小时才会有一次Full GC。
这里就保持默认的设置,每次Full GC之后都执行一次内存碎片整理就可以,JVM参数如下:
“-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=5 -XX:PertenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFaction=92 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0”
Full GC优化的前提是Minor GC的优化,Minor GC优化的前提是合理分配内存空间,合理分配内存空间的前提是对系统运行期间的内存使用模型进行预估。