09、Flink深入:Flink的各种创建执行环境的方法
1. 创建DataSet的执行环境以及WordCount程序
package com.ddkk.hello;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* Author ddkk.com 弟弟快看,程序员编程资料站
* Desc
* 需求:使用Flink完成WordCount-DataSet
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute//如果有print,DataSet不需要调用execute,DataStream需要调用execute
*/
public class WordCount1 {
public static void main(String[] args) throws Exception {
//老版本的批处理API如下,但已经不推荐使用了
//1.准备环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2.准备数据-source
DataSet<String> lineDS = env.fromElements("itcast hadoop spark","itcast hadoop spark","itcast hadoop","itcast");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
/*
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
DataSet<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是一行行的数据
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//将切割处理的一个个的单词收集起来并返回
}
}
});
//3.2对集合中的每个单词记为1
/*
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
DataSet<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
//3.3对数据按照单词(key)进行分组
//0表示按照tuple中的索引为0的字段,也就是key(单词)进行分组
UnsortedGrouping<Tuple2<String, Integer>> groupedDS = wordAndOnesDS.groupBy(0);
//3.4对各个组内的数据按照数量(value)进行聚合就是求sum
//1表示按照tuple中的索引为1的字段也就是按照数量进行聚合累加!
DataSet<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.5排序
DataSet<Tuple2<String, Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
//4.输出结果-sink
result.print();
//5.触发执行-execute//如果有print,DataSet不需要调用execute,DataStream需要调用execute
//env.execute();//'execute()', 'count()', 'collect()', or 'print()'.
}
}
2. 创建DataStream的执行环境以及WordCount程序
package com.ddkk.hello;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Author ddkk.com 弟弟快看,程序员编程资料站
* Desc
* 需求:使用Flink完成WordCount-DataStream
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute
*/
public class WordCount2 {
public static void main(String[] args) throws Exception {
//新版本的流批统一API,既支持流处理也支持批处理
//1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//2.准备数据-source
DataStream<String> linesDS = env.fromElements("itcast hadoop spark","itcast hadoop spark","itcast hadoop","itcast");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
/*
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是一行行的数据
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//将切割处理的一个个的单词收集起来并返回
}
}
});
//3.2对集合中的每个单词记为1
/*
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
//3.3对数据按照单词(key)进行分组
//0表示按照tuple中的索引为0的字段,也就是key(单词)进行分组
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
//3.4对各个组内的数据按照数量(value)进行聚合就是求sum
//1表示按照tuple中的索引为1的字段也就是按照数量进行聚合累加!
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
//4.输出结果-sink
result.print();
//5.触发执行-execute
env.execute();//DataStream需要调用execute
}
}
3. Lambda版的WordCount程序
package com.ddkk.hello;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Author ddkk.com 弟弟快看,程序员编程资料站
* Desc
* 需求:使用Flink完成WordCount-DataStream--使用lambda表达式
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute
*/
public class WordCount3_Lambda {
public static void main(String[] args) throws Exception {
//1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//2.准备数据-source
DataStream<String> linesDS = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
/*
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
//lambda表达式的语法:
// (参数)->{方法体/函数体}
//lambda表达式就是一个函数,函数的本质就是对象
DataStream<String> wordsDS = linesDS.flatMap(
(String value, Collector<String> out) -> Arrays.stream(value.split(" ")).forEach(out::collect)
).returns(Types.STRING);
//3.2对集合中的每个单词记为1
/*
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
/*DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING, Types.INT));*/
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(
(String value) -> Tuple2.of(value, 1)
, TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {})
);
//3.3对数据按照单词(key)进行分组
//0表示按照tuple中的索引为0的字段,也就是key(单词)进行分组
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
//KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy((KeySelector<Tuple2<String, Integer>, String>) t -> t.f0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
//3.4对各个组内的数据按照数量(value)进行聚合就是求sum
//1表示按照tuple中的索引为1的字段也就是按照数量进行聚合累加!
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
//4.输出结果-sink
result.print();
//5.触发执行-execute
env.execute();
}
}
4. 在windos本地创建含有WebUI的Flink执行环境
4.1. 导入依赖
<!--flink的web包,可以在本地idea执行程序时显示web界面-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
4.2. 具体代码
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.text.SimpleDateFormat;
/**
* @date: 2021/7/1
* @Author ddkk.com 弟弟快看,程序员编程资料站
* @desc: 在windos本地创建Flink的含有WebUI的执行环境
*/
public class WebUIForIDEA {
public static void main(String[] args) throws Exception {
// 使用流的执行环境类创建本地并含有WebUI的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env
.addSource(new SourceFunction<String>() {
boolean flag = true;
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
public void run(SourceContext<String> sourceContext) throws Exception {
while (flag) {
sourceContext.collect(sdf.format(System.currentTimeMillis()));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
})
.print("WebUIForIDEA >>>>>");
// 启动执行
env.execute("WebUIForIDEA");
}
}
4.3. 执行效果
访问url:http://localhost:8081/#/job-manager/stdout
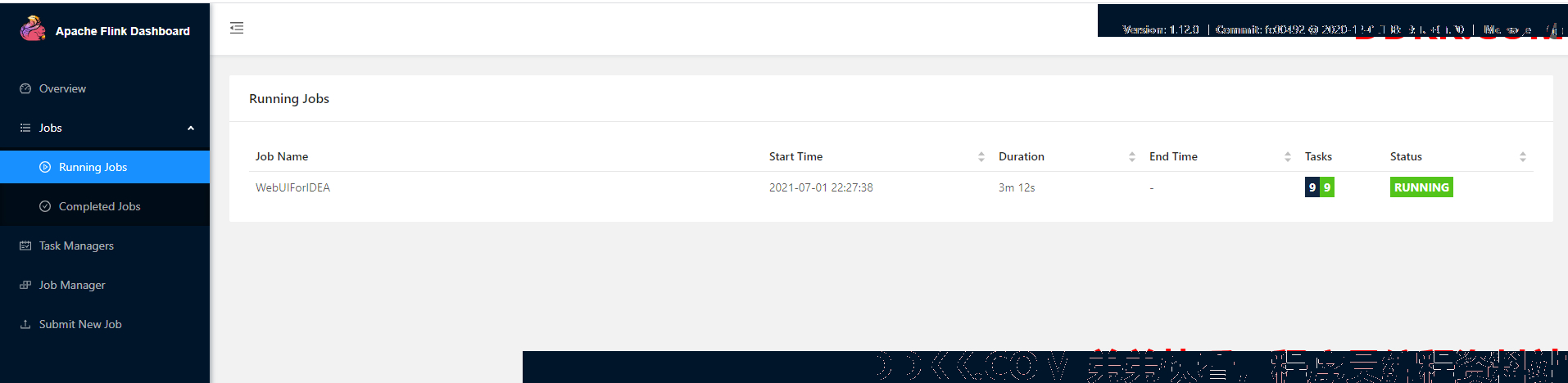
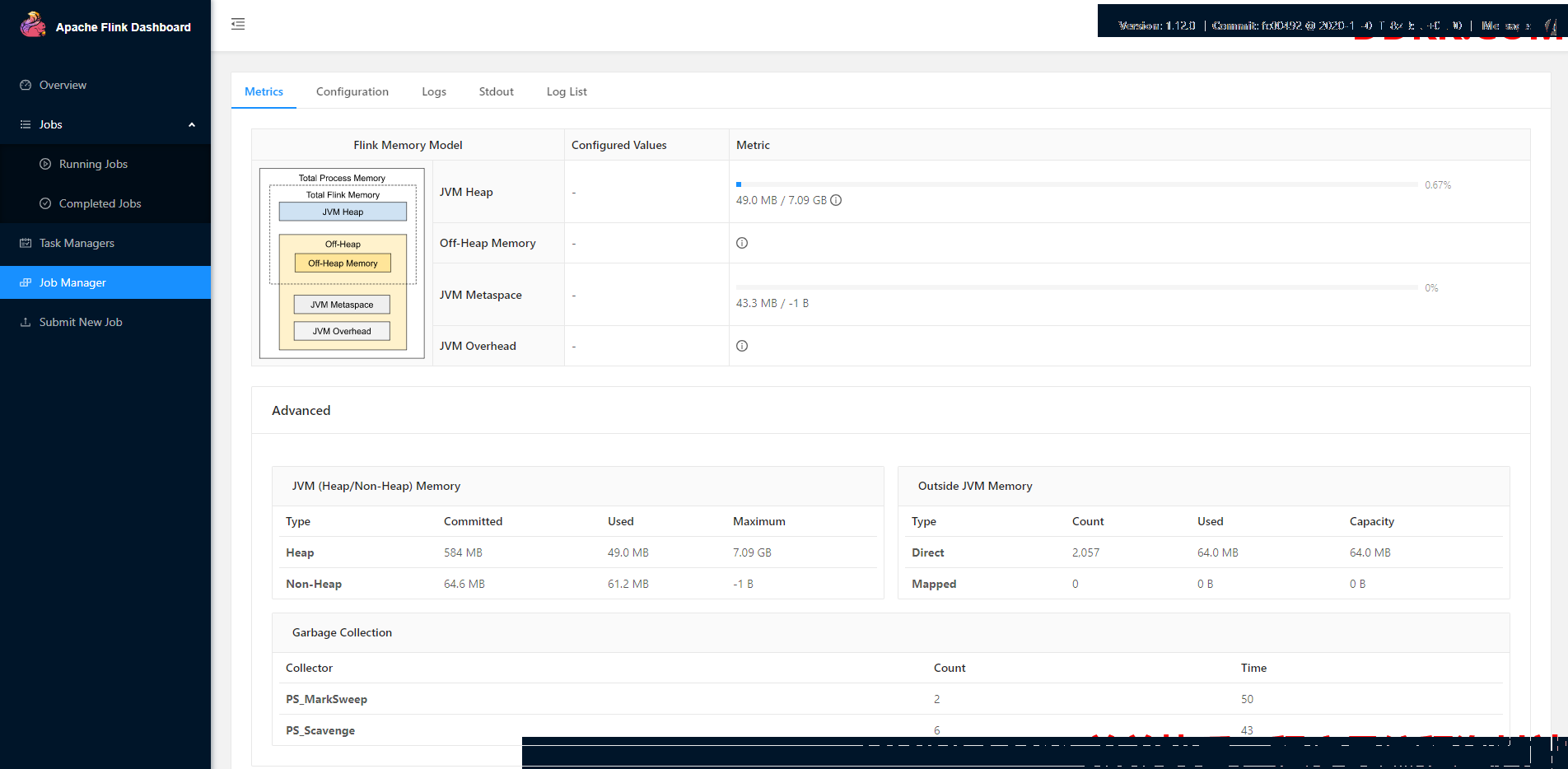
5. 在Yarn上运行Flink程序
步骤一:编写代码 :
package com.ddkk.hello;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Author ddkk.com 弟弟快看,程序员编程资料站
* Desc
* 需求:使用Flink完成WordCount-DataStream--使用lambda表达式--修改代码使适合在Yarn上运行
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute//批处理不需要调用!流处理需要
*/
public class WordCount4_Yarn {
public static void main(String[] args) throws Exception {
//获取参数
ParameterTool params = ParameterTool.fromArgs(args);
String output = null;
if (params.has("output")) {
output = params.get("output");
} else {
output = "hdfs://node1:8020/wordcount/output_" + System.currentTimeMillis();
}
//1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//2.准备数据-source
DataStream<String> linesDS = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
//3.处理数据-transformation
DataStream<Tuple2<String, Integer>> result = linesDS
.flatMap(
(String value, Collector<String> out) -> Arrays.stream(value.split(" ")).forEach(out::collect)
).returns(Types.STRING)
.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING, Types.INT))
//.keyBy(0);
.keyBy((KeySelector<Tuple2<String, Integer>, String>) t -> t.f0)
.sum(1);
//4.输出结果-sink
result.print();
//如果执行报hdfs权限相关错误,可以执行 hadoop fs -chmod -R 777 /
System.setProperty("HADOOP_USER_NAME", "root");//设置用户名
//result.writeAsText("hdfs://node1:8020/wordcount/output_"+System.currentTimeMillis()).setParallelism(1);
result.writeAsText(output).setParallelism(1);
//5.触发执行-execute
env.execute();
}
}
步骤二:打包上传
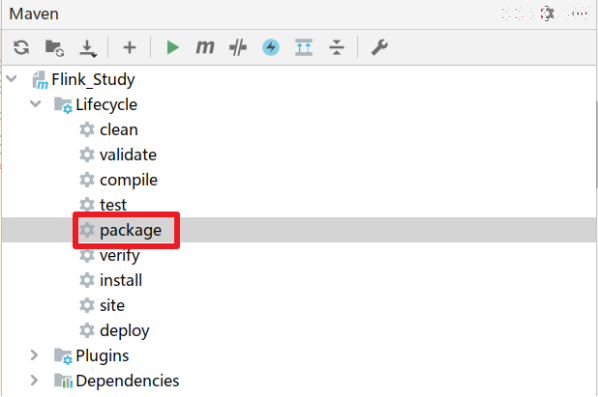


步骤三:提交执行
Apache Flink 1.12 Documentation: Execution Mode (Batch/Streaming)
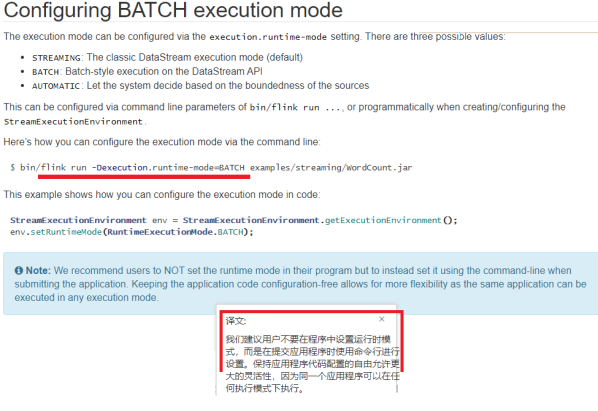
执行命令:
/export/server/flink/bin/flink run -Dexecution.runtime-mode=BATCH -m yarn-cluster -yjm 1024 -ytm 1024 -c com.ddkk.hello.WordCount4_Yarn /root/wc.jar --output hdfs://node1:8020/wordcount/output_xx
步骤四:在web页面观察提交的程序
http://node1:50070/explorer.html#/
或者在Standalone模式下使用web界面提交
注意事项 :
写入HDFS如果存在权限问题进行如下设置:
hadoop fs -chmod -R 777 /
并在代码中添加:
System.setProperty("HADOOP_USER_NAME", "root")