01、Sharding-JDBC 实战:SpringBoot集成

1.背景
- 随着业务数据量的增加,原来所有的数据都是在一个数据库上,网络IO及文件IO都集中在一个数据库上,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。
- 当业务系统的数据容量接近或超过单台服务器的容量,QPS/TPS会受限于单个数据库实例的处理极限。
2.简介
Sharding-JDBC: 是当当网脱离出来的一款用于在客户端的JDBC 层提供的额外服务的轻量级Java框架。适用于微服务的分布式数据访问基础类库,完整地实现了分库分表、读写分离和分布式主键功能,并初步实现了柔性事务。
Sharding-JDBC架构图:
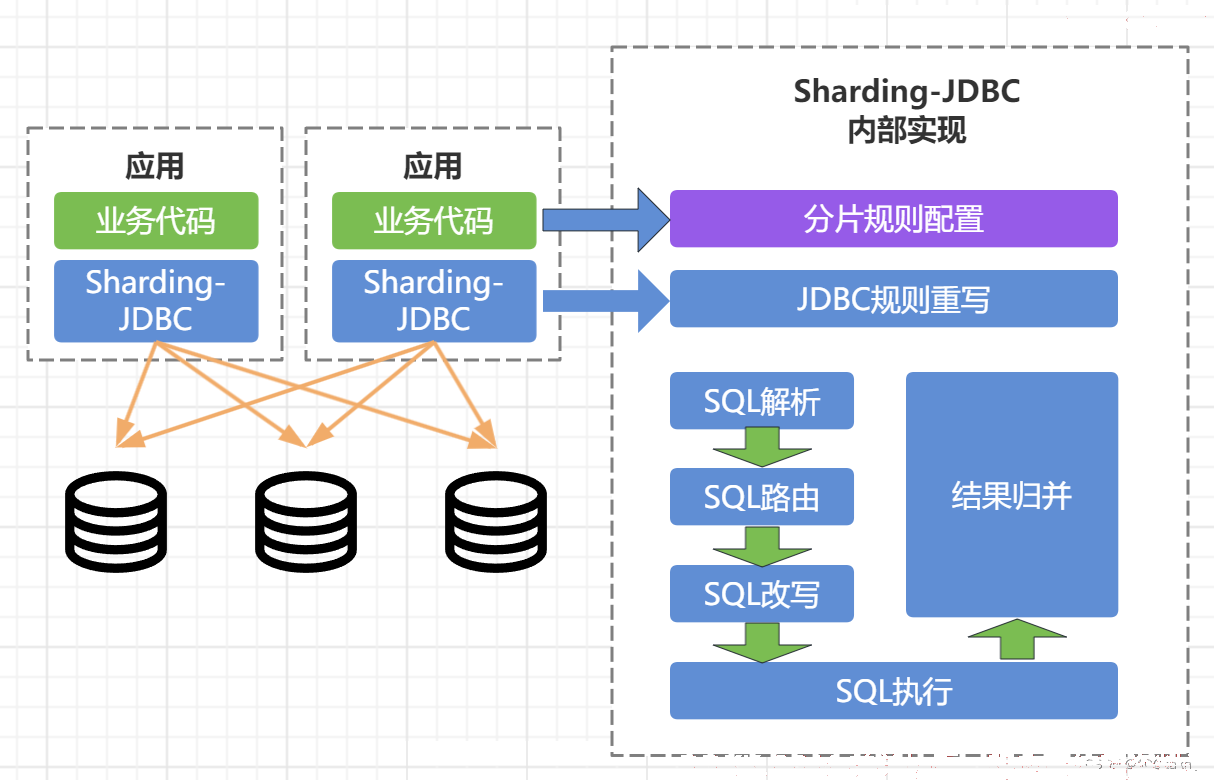
知识拓展:
- 2018 年 5 月,因为增加了 Proxy 的版本和 Sharding-Sidecar(尚未发布),Sharding-JDBC 更名为 Sharding Sphere,从一个客户端的组件变成了一个套件。
Sharding-JDBC 与 Sharding-Proxy 区别:
从设计理念上看确实有一定的相似性。主要流程都是SQL 解析 -> SQL 路由 -> SQL 改写 -> SQL 执行 -> 结果归并。但架构设计上是不同的。
- Sharding-Proxy是基于 Proxy,它复写了 MySQL 协议,将 服务 伪装成一个 MySQL 数据库;
- Sharding-JDBC 是基于 JDBC 的扩展,是以 jar 包的形式提供轻量级服务的。
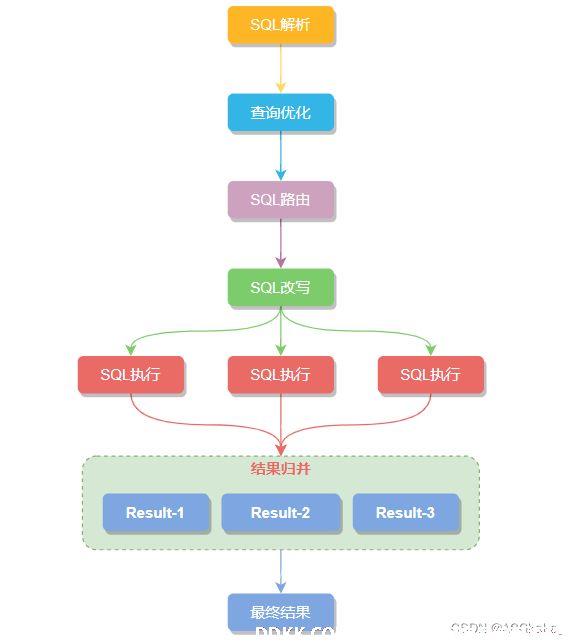
数据表拆分标准:
1、 表的体积大于2G;
2、 表的行数大于1000w,以单表主键等简单形式访问数据;
3、 表的行数大于500w,小范围查询(结果集小于100行)等形式访问数据;
4、 表的行数大于200w,以多表join,范围查询,orderby,groupby,高频率等复杂形式访问数据,由于DML;
5、 数据有时间过期特性的;
只要达到上面任何一个标准,都需要做分表处理。
ShardingJDBC支持SQL:
| 数据库 | 支持状态 |
|---|---|
| MySQL | 支持,完善 |
| PostgreSQL | 支持,完善 |
| SQLServer | 支持 |
| Oracle | 支持 |
| SQL92 | 支持 |
3.依赖与配置
Maven依赖:
<!-- Sharding-JDBC -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.1</version>
</dependency>
yml配置:
spring:
shardingsphere:
打印sql
# props:
# sql:
# show: true
datasource:
names: mydb
mydb:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
数据源其他配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
sharding:
表策略配置
tables:
t_user 是逻辑表
t_user:
分表节点 可以理解为分表后的那些表 比如 t_user_1 ,t_user_2 ,t_user_3
actualDataNodes: mydb.t_user_$->{
1..3}
tableStrategy:
inline:
根据哪列分表
shardingColumn: age
分表算法 例如:age为奇数 -> t_user_2; age为偶数 -> t_user_1
algorithmExpression: t_user_$->{
age % 2 + 1}
分表算法 例如:age为3 -> t_user_3
# algorithmExpression: t_user_$->{age}
分表后,sharding-jdbc的全局id生成策略
# keyGenerator:
# type: SNOWFLAKE
# 对id列采用 sharding-jdbc的全局id生成策略
# column: id
4.表结构(1…3)
-- ------------------------------
-- 用户表1
-- ------------------------------
CREATE TABLE t_user_1 (
id bigint(16) NOT NULL AUTO_INCREMENT COMMENT '主键',
username varchar(64) NOT NULL COMMENT '用户名',
password varchar(64) NOT NULL COMMENT '密码',
age int(8) NOT NULL COMMENT '年龄',
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表1';
-- ------------------------------
-- 用户表2
-- ------------------------------
CREATE TABLE t_user_2 (
id bigint(16) NOT NULL AUTO_INCREMENT COMMENT '主键',
username varchar(64) NOT NULL COMMENT '用户名',
password varchar(64) NOT NULL COMMENT '密码',
age int(8) NOT NULL COMMENT '年龄',
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表2';
-- ------------------------------
-- 用户表3
-- ------------------------------
CREATE TABLE t_user_3 (
id bigint(16) NOT NULL AUTO_INCREMENT COMMENT '主键',
username varchar(64) NOT NULL COMMENT '用户名',
password varchar(64) NOT NULL COMMENT '密码',
age int(8) NOT NULL COMMENT '年龄',
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表3';
5.测试验证
测试代码:
package com.demo;
import com.demo.module.entity.TUser;
import com.demo.module.service.TUserService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
class SpringbootDemoApplicationTests {
@Autowired
private TUserService userService;
@Test
void saveTest() {
List<TUser> users = new ArrayList<>(3);
users.add(new TUser("ACGkaka_1", "123456", 10));
users.add(new TUser("ACGkaka_2", "123456", 11));
users.add(new TUser("ACGkaka_3", "123456", 12));
userService.saveBatch(users);
}
@Test
void listTest() {
List<TUser> users = userService.list();
System.out.println(">>>>>>>>>> 【Result】<<<<<<<<<< ");
users.forEach(System.out::println);
}
}
5.1 批量保存
执行结果(t_user_1):

执行结果(t_user_2):

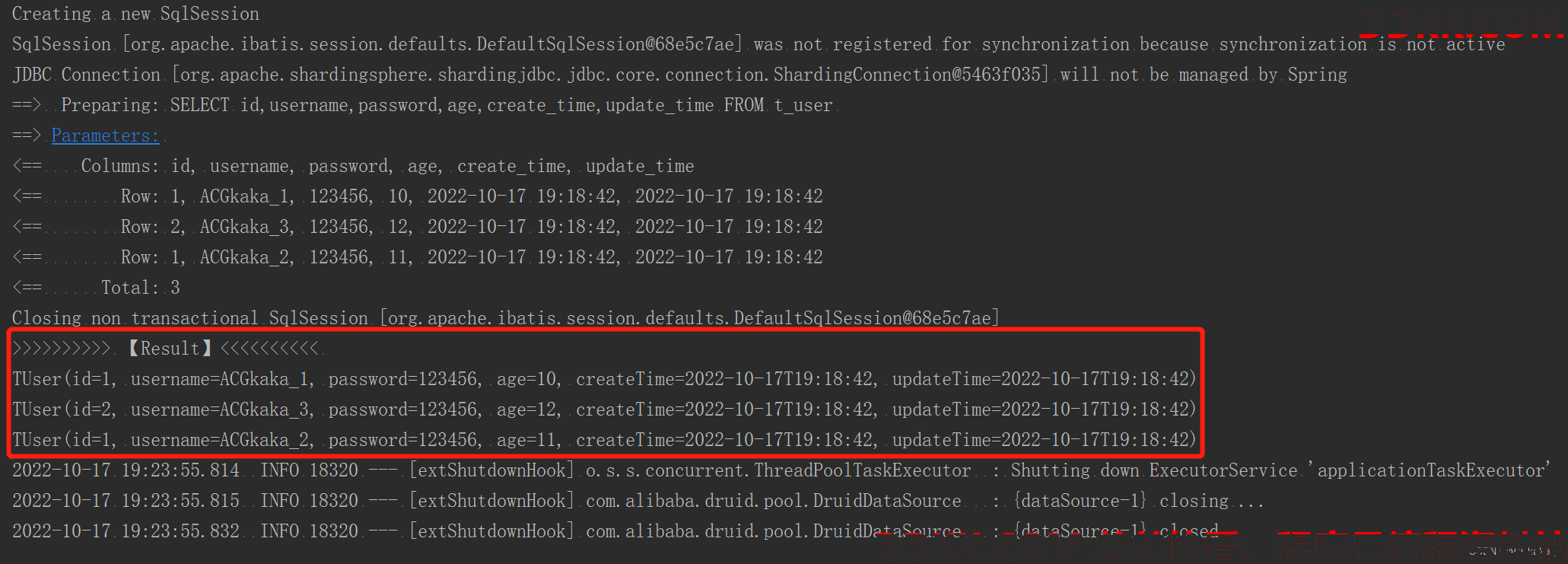
5.2 列表查询
执行结果:
6.源码地址
地址: https://gitee.com/acgkaka/SpringBootExamples/tree/master/springboot-sharding-jdbc
整理完毕,完结撒花~
参考地址:
1、 sharding-jdbc与Sharding-Proxy,https://www.jianshu.com/p/20c0d4114632;
2、 mysql数据库多少数据才考虑拆分数据表table,https://www.zzzyk.com/show/14e6b51d08c6578f.htm;
3、 Sharding-JDBC实战(史上最全),https://blog.csdn.net/crazymakercircle/article/details/123420859;