03、Kafka 实战 - kafka中的基本概念
消息和批次
消息,Kafka 里的数据单元,也就是我们一般消息中间件里的消息的概念(可以比作数据库中一条记录)。消息由字节数组组成。消息还可以包含键 (可选元数据,也是字节数组),主要用于对消息选取分区。
作为一个高效的消息系统,为了提高效率,消息可以被分批写入 Kafka。批次就是一组消息,这些消息属于同一个主题和分区。如果只传递单个消息, 会导致大量的网络开销,把消息分成批次传输可以减少这开销。但是,这个需要权衡(时间延迟和吞吐量之间),批次里包含的消息越多,单位时间内 处理的消息就越多,单个消息的传输时间就越长(吞吐量高延时也高)。如果进行压缩,可以提升数据的传输和存储能力,但需要更多的计算处理。
对于Kafka 来说,消息是晦涩难懂的字节数组,一般我们使用序列化和反序列化技术,格式常用的有 JSON 和 XML,还有 Avro(Hadoop 开发的一款 序列化框架),具体怎么使用依据自身的业务来定。 主题和分区 Kafka 里的消息用主题进行分类(主题好比数据库中的表),主题下有可以被分为若干个分区(分表技术)。分区本质上是个提交日志文件,有新消 息,这个消息就会以追加的方式写入分区(写文件的形式),然后用先入先出的顺序读取
主题和分区
Kafka 里的消息用主题进行分类(主题好比数据库中的表),主题下有可以被分为若干个分区(分表技术)。分区本质上是个提交日志文件,有新消 息,这个消息就会以追加的方式写入分区(写文件的形式),然后用先入先出的顺序读取。
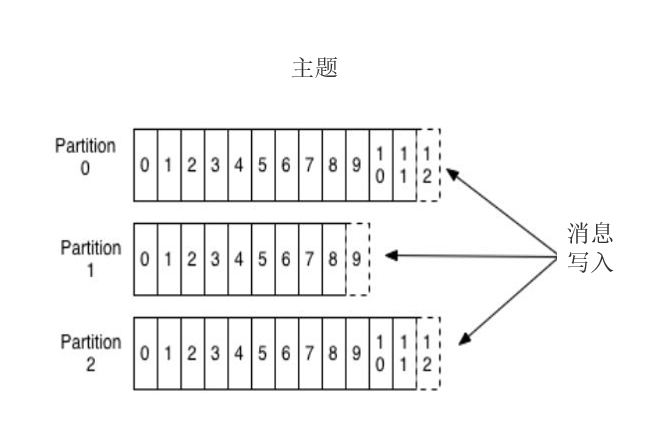
但是因为主题会有多个分区,所以在整个主题的范围内,是无法保证消息的顺序的,单个分区则可以保证。
Kafka 通过分区来实现数据冗余和伸缩性,因为分区可以分布在不同的服务器上,那就是说一个主题可以跨越多个服务器(这是 Kafka 高性能的一个 原因,多台服务器的磁盘读写性能比单台更高)。
前面我们说 Kafka 可以看成一个流平台,很多时候,我们会把一个主题的数据看成一个流,不管有多少个分区。
生产者和消费者、偏移量、消费者群
就是一般消息中间件里生产者和消费者的概念。一些其他的高级客户端 API,像数据管道 API 和流式处理的 Kafka Stream,都是使用了最基本的生产 者和消费者作为内部组件,然后提供了高级功能。
生产者默认情况下把消息均衡分布到主题的所有分区上,如果需要指定分区,则需要使用消息里的消息键和分区器。 消费者订阅主题,一个或者多个,并且按照消息的生成顺序读取。
消费者通过检查所谓的偏移量来区分消息是否读取过。偏移量是一种元数据,一 个不断递增的整数值,创建消息的时候,Kafka 会把他加入消息。在一个主题中一个分区里,每个消息的偏移量是唯一的。每个分区最后读取的消息偏移 量会保存到 Zookeeper 或者 Kafka 上,这样分区的消费者关闭或者重启,读取状态都不会丢失。
多个消费者可以构成一个消费者群组。怎么构成?共同读取一个主题的消费者们,就形成了一个群组。群组可以保证每个分区只被一个消费者使用
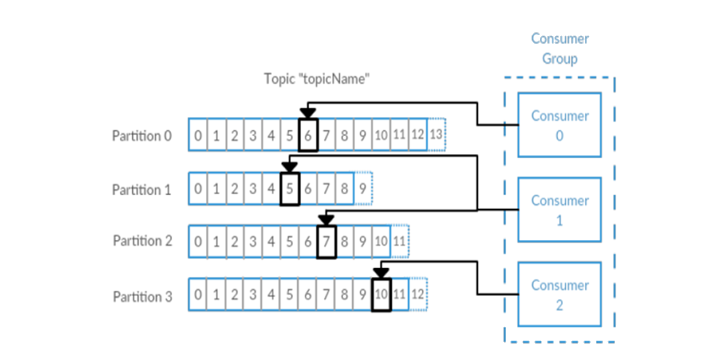
消费者和分区之间的这种映射关系叫做消费者对分区的所有权关系,很明显,一个分区只有一个消费者,而一个消费者可以有多个分区。
(吃饭的故事:一桌一个分区,多桌多个分区,生产者不断生产消息(消费),消费者就是买单的人,消费者群组就是一群买单的人),一个分区只能 被消费者群组中的一个消费者消费(不能重复消费),如果有一个消费者挂掉了,另外的消费者接上)
Broker 和集群
Broker 和集群
一个独立的 Kafka 服务器叫 Broker。broker 的主要工作是,接收生产者的消息,设置偏移量,提交消息到磁盘保存;为消费者提供服务,响应请求, 返回消息。在合适的硬件上,单个 broker 可以处理上千个分区和每秒百万级的消息量。(要达到这个目的需要做操作系统调优和 JVM 调优)
多个broker 可以组成一个集群。每个集群中 broker 会选举出一个集群控制器。控制器会进行管理,包括将分区分配给 broker 和监控 broker。
集群里,一个分区从属于一个 broker,这个 broker 被称为首领。但是分区可以被分配给多个 broker,这个时候会发生分区复制。
集群中Kafka 内部一般使用管道技术进行高效的复制。
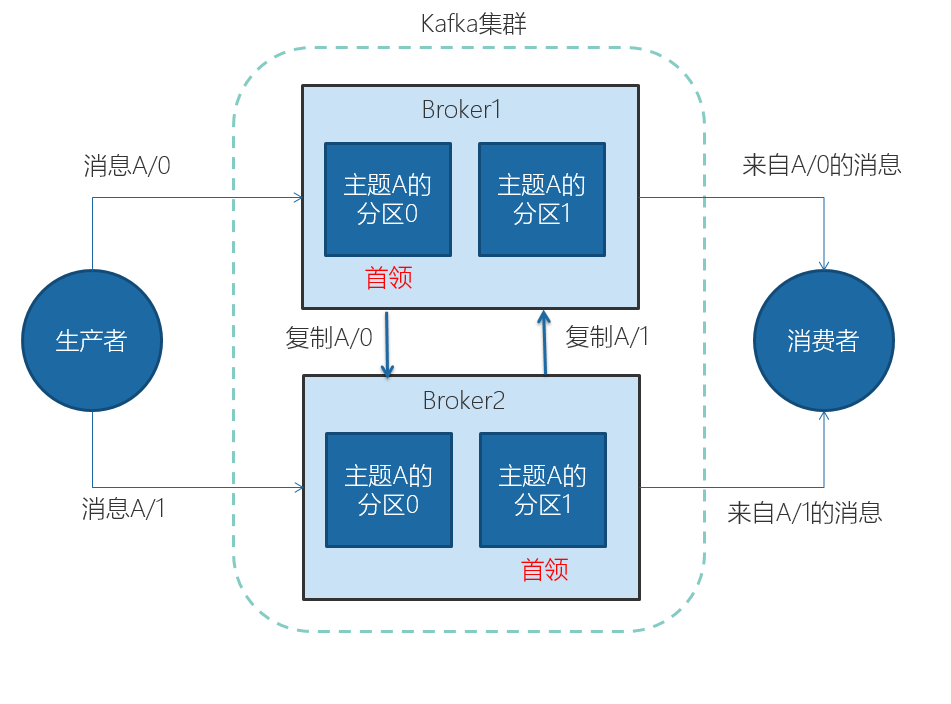
分区复制带来的好处是,提供了消息冗余。一旦首领 broker 失效,其他 broker 可以接管领导权。当然相关的消费者和生产者都要重新连接到新的首 领上
保留消息
在一定期限内保留消息是 Kafka 的一个重要特性,Kafka broker 默认的保留策略是:要么保留一段时间(7 天),要么保留一定大小(比如 1 个 G)。 到了限制,旧消息过期并删除。但是每个主题可以根据业务需求配置自己的保留策略(开发时要注意,Kafka 不像 Mysql 之类的永久存储)