10、Java多线程:线程管理
9.1 线程组
类似于在计算机中使用文件夹管理文件,也可以使用线程组来管理线程,在线程组中定义一组相似(相关)的线程。也可以在线程组中定义子线程组。
Thread类有几个构造方法,其中一个允许在创建线程时指定线程组,如果在创建线程时没有指定线程组,则该线程就属于父线程所在的线程组。
JVM在创建main线程时会为它指定一个线程组,因此每个Java线程都有一个线程组与之关联,可以调用线程的getThreadGroup()方法返回该线程的线程组。
代码演示:
package threadgroup;
public class Test01 {
public static void main(String[] args) {
//返回当前main线程的线程组
ThreadGroup mainGroup = Thread.currentThread().getThreadGroup();
// System.out.println(mainGroup);
//定义线程组,如果没有指定它的父线程组,那么它就是当前这个线程组的子线程组
ThreadGroup group1 = new ThreadGroup("group1");
// System.out.println(group1);
// System.out.println(group1.getParent());
//也可以指定父线程组
ThreadGroup group2 = new ThreadGroup(mainGroup, "group2");
// System.out.println(group2.getParent());
//创建线程时指定所属线程组
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread());
}
};
//创建线程时,如果没有指定线程组,默认归属到父线程的线程组中
//我们在main线程中创建了t线程,所以t线程是main线程的子线程
//如果t线程没有指定线程组,那么它的线程组就是默认为main线程的线程组
Thread t = new Thread(r);
System.out.println(t);
//创建线程时,可以指定线程所属的线程组
Thread t2 = new Thread(group1, r, "t2");
Thread t3 = new Thread(group2, r, "t3");
System.out.println(t3);
}
}
线程组的基本操作:
activeCount():返回当前线程组及子线程组中活动线程的数量(近似值)。
activeGroupCount():返回当前线程组及其子线程组中活动线程组的数量(近似值)。
enumerate(Thread[] list):将当前线程组及其子线程组中的活动线程复制参数数组中。
enumerate(ThreadGroup[] list):将当前线程组中的活动线程组及其子线程组复制到参数数组中。
getMaxPriority():返回线程组的最大优先级,默认是10。在这个线程组中的线程的优先级不能超过这个值。
getName():返回线程组的名称
getParent():返回父线程组
interrupt():中断线程组中的所有线程
isDaemon():判断当前线程组是否为守护线程组
list():将当前线程组当中的活动线程打印出来
parentOf(ThreadGroup g):判断当前线程组是否为参数线程组的子线程组
setDaemon():设置线程组为守护线程组
复制线程组中的线程及其子线程:
enumerate(Thread[] list):将当前线程组及其子线程组中的活动线程复制参数数组中。
enumerate(Thread[] list, boolean recursive):如果第二个参数为false,则不复制它的子线程组的h活动线程。
enumerate(ThreadGroup[] list):将当前线程组中的活动线程组及其子线程组中的线程组复制到参数数组中。
enumerate(ThreadGroup[] list, boolean recurse):不复制子线程组中的线程组。
package threadgroup;
import java.util.concurrent.TimeUnit;
public class Test03 {
public static void main(String[] args) {
ThreadGroup mainGroup = Thread.currentThread().getThreadGroup();
Runnable r = new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1000);
} catch (InterruptedException e){
e.printStackTrace();
}
}
};
Thread m1 = new Thread(mainGroup, r);
Thread m2 = new Thread(mainGroup, r);
ThreadGroup group1 = new ThreadGroup("group1");
Thread g1 = new Thread(group1, r);
Thread g2 = new Thread(group1, r);
m1.start();
m2.start();
g1.start();
g2.start();
ThreadGroup group2 = new ThreadGroup(group1, "group2");
Thread[] list = new Thread[mainGroup.activeCount()];
ThreadGroup[] groupList = new ThreadGroup[mainGroup.activeGroupCount()];
mainGroup.enumerate(list, false);
mainGroup.enumerate(groupList, false);
System.out.println("开始打印");
System.out.println(list.length);
System.out.println(groupList.length);
for(Thread thread : list) {
System.out.println(thread);
}
for(ThreadGroup group : groupList) {
System.out.println(group);
}
}
}
线程组的批量中断:
线程组的interrupt()方法可以给线程组中的所有线程添加中断标志。
package threadgroup;
import java.util.concurrent.TimeUnit;
/**
* 线程组的批量中断
*/
public class Test04 {
public static void main(String[] args) throws InterruptedException {
Runnable r = new Runnable() {
@Override
public void run() {
while(!Thread.interrupted()) {
System.out.println(Thread.currentThread().getName() + "is running");
}
System.out.println(Thread.currentThread().getName() + "is interrupted");
}
};
ThreadGroup mainGroup = Thread.currentThread().getThreadGroup();
Thread t1 = new Thread(mainGroup, r);
Thread t2 = new Thread(mainGroup, r);
ThreadGroup group1 = new ThreadGroup(mainGroup, "g1");
Thread t3 = new Thread(group1, r);
Thread t4 = new Thread(group1, r);
t1.start();
t2.start();
t3.start();
t4.start();
TimeUnit.SECONDS.sleep(1);
mainGroup.interrupt();
}
}
设置守护线程组:
守护线程是为其他线程服务的,当JVM中只有守护线程时,守护线程会被销毁,JVM退出。
线程组的setDaemon(true)方法可以把线程组设置为守护线程组,当守护线程组中没有活动线程时,守护线程组被销毁。
守护线程组的守护属性,与其线程的守护属性无关。
9.2 捕获线程的执行异常
在线程的run方法中,如果有受检异常必须进行捕获处理,如果想要获得run()方法中出现的运行时异常信息,可以通过回调UncaughtExceptionHandler接口获得哪个线程出现了运行时异常。在Thread类中有关处理运行时异常的方法有:
getDefaultUncaughtExceptionHandler() 获得全局的(默认的)UncaughtExceptionHandler
getUncaughtExceptionHandler() 获得当前线程的UncaughtExceptionHandler
setDefaultUncaughtExceptionHandler() 设置全局的UncaughtExceptionHandler
setUncaughtExceptionHandler() 设置当前线程的UncaughtExceptionHandler
当线程运行过程中出现异常,JVM会调用Thread类的dispatchUncaughtException(Throwable e)方法,该方法会调用getUncaughtExceptionHandler().uncaughtException(this, e)。所以如果想要获得线程中出现的异常的信息,就需要设置线程的UncaughtExceptionHandler。
如果当前线程没有设定UncaughtExceptionHandler,则会调用线程组的,如果线程组也没有设定,则直接把异常的栈信息定向到System.err中。
package threadException;
/**
* 设置线程的UncaughtExceptionHandler回调接口
*/
public class Test01 {
public static void main(String[] args) {
//设置全局的回调接口
Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
//t参数,表示发现异常的线程,e就是该线程中的异常
System.out.println(t.getName() + "发生了异常:" + e.getMessage());
}
});
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "is running");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
//受检异常必须捕获处理
e.printStackTrace();
}
System.out.println(12 / 0);
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
String txt = null;
System.out.println(txt.length());
}
});
t1.start();
t2.start();
}
}
9.3 注入Hook钩子线程
现在很多软件,包括MySQL、Zoonkeeper、kafka等都存在Hook线程的校验机制,目的是校验进程是否已启动,防止重复启动程序。
Hook线程也称钩子线程,在JVM退出的时候会执行Hook线程。
比如为了防止重复启动线程,程序启动时会创建一个.lock文件,那么在程序结束时就需要删除这个.lock文件,我们通过注入一个Hook线程来完成删除.lock文件的操作。
关于Hook线程更多的知识可以查看这个博客:Java并发编程系列---Hook线程_逆流而上的博客-CSDN博客_hook线程
代码示例(防止程序重复启动):
package threadException;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.sql.Time;
import java.util.concurrent.TimeUnit;
/**
* Hook线程防止程序重复启动
*/
public class Test02 {
public static void main(String[] args) throws IOException, InterruptedException {
//1)注入hook线程,防止程序重复启动,JVM退出时删除.lock文件
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
System.out.println("JVM退出,会启动当前hook线程,在hook线程中删除.lock文件");
getLockFile().toFile().delete();
}
}));
if(getLockFile().toFile().exists()) {
throw new RuntimeException("程序已启动");
} else { //文件不存在,说明程序第一次启动
getLockFile().toFile().createNewFile();
System.out.println("程序第一次启动,创建lockfile");
}
for(int i = 0; i < 10; i++) {
System.out.println("程序正在运行");
TimeUnit.SECONDS.sleep(1);
}
}
private static Path getLockFile() {
return Paths.get("", "tmp.lock");
}
}
9.4 线程池
在真实生产环境中,可能需要很多线程来支撑整个应用,当线程数量非常多时,反而会耗尽CPU资源。如果不对线程进行控制与管理,反而会影响程序的性能。
线程池就是有效使用线程的一种常用方式。线程池内部可以预先创建一定数量的工作线程,客户端代码直接将任务作为一个对象提交给线程池,线程池将这些任务缓存在工作队列中,线程池中的工作线程不断地从队列中取出任务并执行。
JDK对线程池的支持:
JDK提供了一套Executor框架,可以帮助开发人员有效地使用线程池。
package threadpool;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test01 {
public static void main(String[] args) {
//创建有固定大小(5)的线程池
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5);
//向线程池中提交18个任务
for(int i = 0; i < 18; i++) {
fixedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getId() + "编号的任务正在正式,开始时间:" + System.currentTimeMillis());
}
});
}
}
}
线程池的计划任务:
package threadpool;
import java.sql.Time;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 线程池的计划任务
*/
public class Test02 {
public static void main(String[] args) {
//创建一个有调度功能的线程池
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(10);
//延迟2秒后执行任务
scheduledExecutorService.schedule(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getId() + "--" + System.currentTimeMillis());
}
}, 2, TimeUnit.SECONDS);
// //以固定的频率执行任务。在3秒后执行任务,以后每隔5秒重新执行一次
// scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
// @Override
// public void run() {
// System.out.println(Thread.currentThread().getId() + "--" + System.currentTimeMillis());
// try {
// TimeUnit.SECONDS.sleep(3); //如果任务执行时间超过了时间间隔,则任务完成后立即执行下个任务。
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// }
// }, 3, 2, TimeUnit.SECONDS);
//上一次任务执行完后,在固定延迟后再次执行该任务。
//以下代码中,不管任务执行多长时间,总是任务完成后间隔两秒开启下个任务
scheduledExecutorService.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getId() + "--" + System.currentTimeMillis());
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, 3, 2, TimeUnit.SECONDS);
}
}
核心线程池的底层实现
查看Executors工具类中newCachedThreadPool()、newSingleThreadExecutor()、newFixedThreadPool()的源码:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
Executors工具类中返回线程池的方法底层都是ThreadPoolExecutor线程池的封装。
ThreadPoolExecutor()构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
参数说明:
corePoolSize:指定线程池中的核心线程数量
maximumPoolSize:指定线程池中最大线程数量
keepAliveTime:当线程池中线程的数量超过corePoolSize时,多余的空闲线程的存活时长
unit:keepAliveTime时长单位
workQueue:任务队列,把任务提交到该任务队列中等待执行
threadFactory:线程工厂,用于创建线程的
handler:拒绝策略,当任务太多来不及处理时,如何拒绝
workQueue工作队列是指提交未执行任务的队列,它是BlockingQueue接口的对象,仅用于存储Runnable任务。根据队列功能分类,在ThreadPoolExecutor构造方法中可以使用一下几种阻塞队列:
1)直接提交队列,由SynchronousQueue对象提供,该队列没有容量,来一个任务创建一个线程。如果没有空闲线程,则尝试创建新的线程。如果线程数量已达到最大值而无法创建线程时,则执行拒绝策略。
2)有界任务队列,有ArrayBlockingQueu实现,在创建该对象时,可以指定一个容量。当有任务需要执行时,如果线程数少于核心线程数,则创建新的线程,否则将任务加入等待队列。如果队列满,则在线程数少于最大线程数的情况下,创建新的线程。否则,无法加入,执行拒绝策略。
3)无界任务队列,由LinkedblockingQueue对象实现,与有界队列相比,除非系统资源耗尽,否则不存在任务入队失败的情况。线程数少于核心线程数时,先创建线程。否则加入阻塞队列。
4)优先任务队列,通过privateBlockingQueue实现的,是带有任务优先级的队列,一个特殊的无界队列。在这个队列中,优先级高的任务先执行。
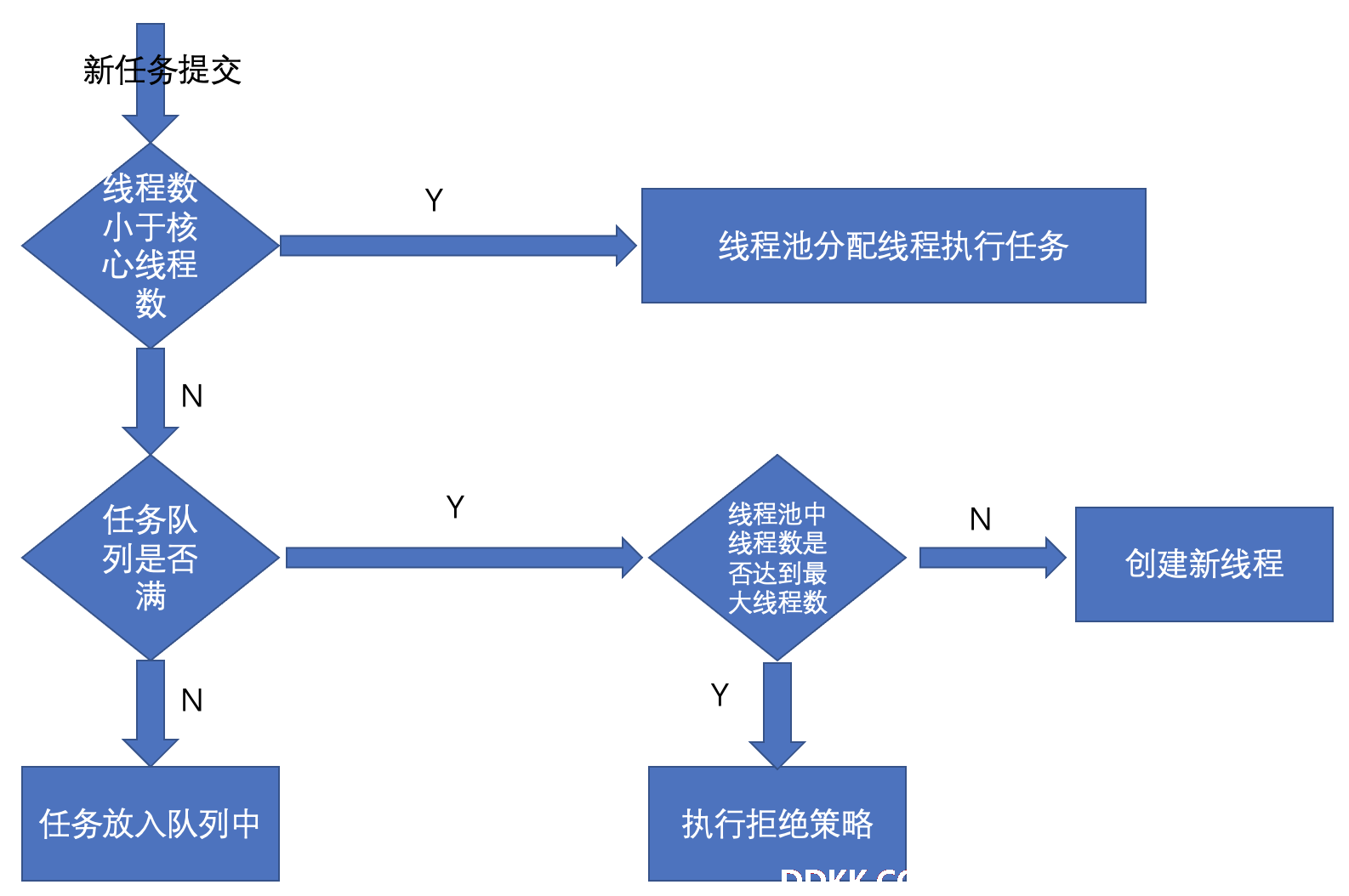
newCacheThreadPool:来一个任务创建一个线程,适合时间短频率高的任务。
newFixedThreadPool:最大线程数等于核心线程数,如果没有空闲线程,任务会放到无界队列中。
newSingleThreadExecutor:核心线程数和最大线程数都是1,任何时刻只有1个线程在执行1个任务。如果没有空闲线程,任务会放到无界队列中。
拒绝策略:
1)AbortPolicy:会抛出异常
2)CallerRunsPolicy:只要线程池没关闭,会在调用者线程中运行当前被丢弃的任务
3)DiscardOldestPolicy:将任务队列中最早加入的任务丢弃,并提交新任务
4)DiscardPolicy:直接丢弃这个无法处理的任务,不会超出异常
Executors工具类提供的静态方法返回的线程池默认的拒绝策略是AbortPolicy策略。
ThreadFactory(线程工厂):
是一个接口,接口中只有一个方法,就是用来创建线程的:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
可以在定义线程池的时候自定义线程工厂:
package threadpool;
import sun.nio.ch.ThreadPool;
import java.sql.Time;
import java.util.Random;
import java.util.concurrent.*;
/**
* 自定义线程工厂
*/
public class Test04 {
public static void main(String[] args) throws InterruptedException {
Runnable r = new Runnable() {
@Override
public void run() {
int num = new Random().nextInt(10);
System.out.println(Thread.currentThread().getId() + "--" + System.currentTimeMillis() + "开始睡眠");
try {
TimeUnit.SECONDS.sleep(num);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
//创建线程池,使用自定义线程工厂
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 5, 0,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
//根据参数r接受的任务,创建一个线程
Thread thread = new Thread(r);
thread.setDaemon(true); //设置为守护线程,主线程执行完毕,线程池中的线程会自动退出
return thread;
}
});
for(int i = 0; i < 20; i++) {
threadPoolExecutor.submit(r);
}
TimeUnit.SECONDS.sleep(5);
}
}
监控线程池:
ThreadPoolExecutor提供了一组方法用于监控线程池:
intgetActiveCount() 获得线程池中当前活动线程的数量
long getCompletedTaskCount() 获得线程池完成任务的数量
intgetCorePoolSize() 线程池中核心线程的数量
intgetLargestPoolSize() 返回线程池曾经达到的线程的最大数
intgetMaximumPoolSize() 返回线程池的最大线程容量
intgetPoolSize() 返回当前线程池的大小
long getTaskCount() 返回线程池收到的任务数量