01、MyCat 实战 - MyCat 使用、名词介绍
1.什么是MyCat
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品 (官网介绍更详细,跳转MyCat 官网:http://www.mycat.io/)
2.MyCat 数据库中间件
MyCat是一个介于数据库与应用服务之间,进行数据处理与交互的中间服务,如下图所示
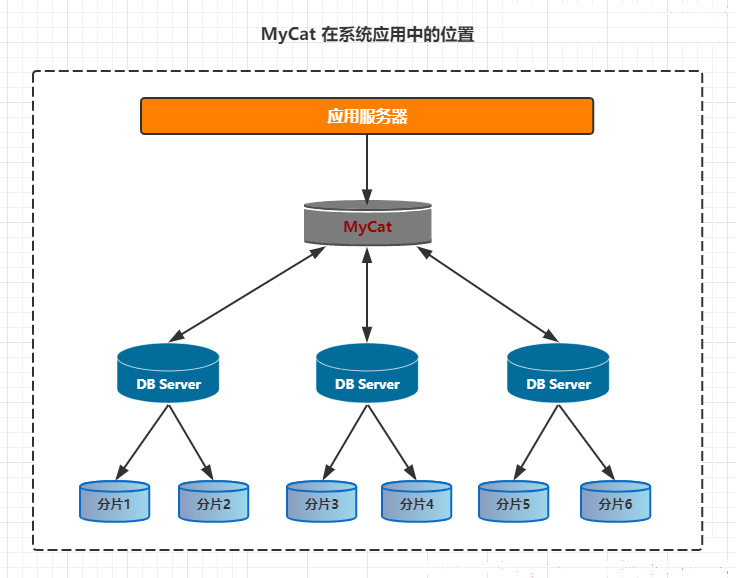
通俗点讲,应用层可以将它看作是一个数据库的代理(或者直接看成加强版数据库)。但是由于真正的数据库需要存储引擎,而 Mycat 并没有存储引擎,Mycat服务不保存真正的数据,所以并不是完全意义的分布式数据库系统。所以称Mycat这样类型的数据库中间代理服务的产品为数据库中间件。
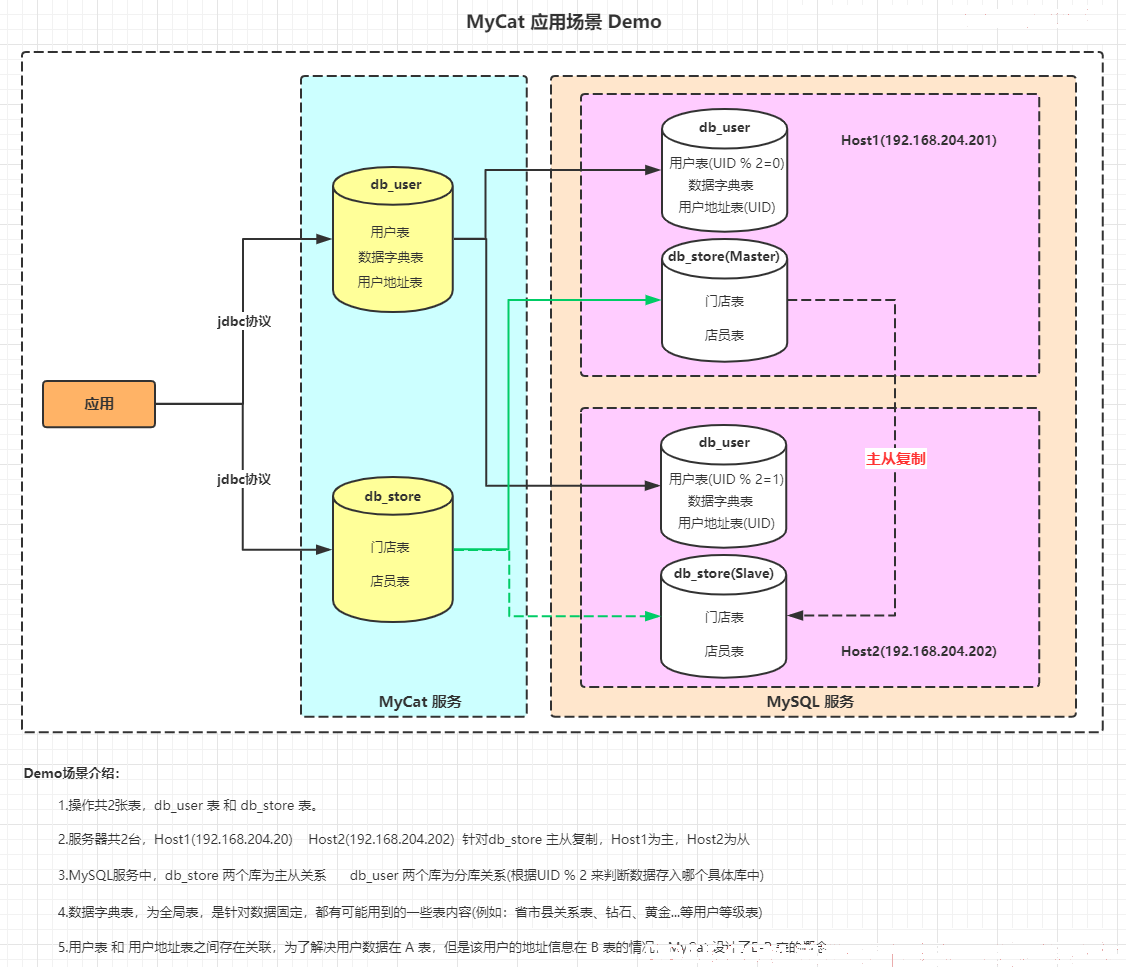
3.MyCat使用场景
4.MyCat名词介绍
以3.MyCat使用场景 为例来介绍
1.逻辑库
MyCat 只是一个中间服务,可以将 MyCat 理解为一个数据库,提供数据库服务。但是 MyCat 的数据并不是真实存在物理环境的,而是加载实际数据库中的数据。
场景中,db_user 和 db_store 就是两个逻辑库,真正的数据源还是来源于 MySQL 服务中的两台实际 MySQL 数据库。
在MyCat 中,逻辑库的定义位于 conf/schema.xml 文件中,用 <schema> 标签定义。

2.逻辑表
MyCat 中有逻辑库的存在,也就有逻辑表的存在。逻辑库中的表就是逻辑表。
逻辑表的数据来源,可以是数据进行切分后,分布在一个或多个分片库中的数据。针对不同的数据分布和管理特点,我们将逻辑表分为 ①分片表 ②全局表 ③ER表 ④非分片表 四种类型。
在MyCat 中, <schema>标签中使用<table>标签来完成逻辑表的定义。

3.分片表
分片表:是指那些原本有很大数据的表,需要切分到多个表。这样,每个分片都有表的一部分数据,所有分片数据的合集构成了完整的表数据
场景中,db_user 库中的 users 表就是一个分片表,通过userId 字段取模的方式进行数据的水平切分。
在MyCat 中,分片表的定义位于 <schema> 标签下,使用 <table>标签来定义

4.分片规则
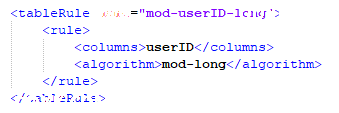
将数据量大的表,切分到多个数据分片的策略,下图中 rule="mod-userID-long" 就是分片规则,

mod-userID-long 为分片规则的名称,在 MyCat 的 conf/rule.xml 文件中配置,具体配置规则如下图所示。

5.全局表
一个真实的业务系统中,往往存在大量的类似数据字典表的表,数据字典表具有以下几个特性:
- 数据变动不频繁;
- 数据规模不大,数据量在十万以内;
- 存在跟其他表(特别是分片表)有一点的关联查询要求。
为了解决表与表的join查询,MyCat 提倡大家将具有上诉特点的表通过数据冗余的方式(全局表的定义)进行解决,即所有的分片都有一份数据的拷贝。通过 MyCat 来完成对这类表的数据的修改,新增,删除操作时,所有的分片数据都将受到影响。

6.E-R表
关系型数据库是基于实体关系模型(Entity-Relationship Model)之上,通过其描述了真实世界中事物与关系,MyCat 中的 ER 表即是来源于此。
根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 Join 不会跨库操作。
场景中的案例,用户表是分片表,用户地址表与用户表之间存在一对多的关系,若通过分片规则,将用户表中的张三分在了分片1,则最好的数据存储方式是将张三的用户地址信息跟随张三一起分配在分片1中。
这样一种表分组的设计方式是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
在MyCat 中,E-R表的定义位于 schema.xml 中 <schema> 标签下,使用<childTable>标签进行描述和定义。

7.非分片表
一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
在MyCat 中,非分片表在 schema.xml 中 <schema>标签下,使用 <table> 标签进行描述和定义

8.分片节点
大数据表进行数据切分后,每个表分片所在的数据库就是分片节点,狭义的理解可以认为一个DB实例就是一个节点,
在MyCat 中,分片节点在 schema.xml 中使用 <dataNode> 进行分片节点的定义(定义与<schema>标签同级哦)
场景中的案例,db_store 采用主从复制,db_user 采用分片来进行存储,配置如下(分片节点的配置,配合节点主机配置来一起使用,节点主机配置 见 9.节点主机 部分)

9.节点主机
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机。
为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机
在MyCat 中,节点主机在 schema.xml 中使用 <dataHost> 进行分片节点的定义(定义与<schema>标签同级哦)

附录:附一份 schema.xml 配置文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 逻辑库配置 -->
<!-- 一个schema标签就是一个逻辑库 -->
<schema name="db_store" checkSQLschema="false" sqlMaxLimit="100">
<table name="store" dataNode="db_store_dataNode" primaryKey="storeID"/>
<table name="employee" dataNode="db_store_dataNode" primaryKey="employeeID"/>
</schema>
<!-- 分片库 -->
<schema name="db_user" checkSQLschema="false" sqlMaxLimit="100">
<!-- 全局表 -->
<table name="data_dictionary" type="global" dataNode="db_user_dataNode1,db_user_dataNode2" primaryKey="dataDictionaryID"/>
<!-- 分片表 --> <!-- rule="mod-userID-long" 是分片规则,定义在rule.xml文件中-->
<table name="users" dataNode="db_user_dataNode$1-2" rule="mod-userID-long" primaryKey="userID">
<!-- ER表 -->
<childTable name="user_address" joinKey="userID" parentKey="userID" primaryKey="addressID"/>
</table>
</schema>
<!-- 节点配置(即数据来源于几台主机) -->
<!-- db_store(主从复制) -->
<dataNode name="db_store_dataNode" dataHost="db_storeHOST" database="db_store" />
<!-- db_user -->
<dataNode name="db_user_dataNode1" dataHost="db_userHOST1" database="db_user" />
<dataNode name="db_user_dataNode2" dataHost="db_userHOST2" database="db_user" />
<!-- 节点主机配置 -->
<!-- 配置db_store的节点主机 -->
<dataHost name="db_storeHOST" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.204.201:3306" user="root" password="root">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="192.168.204.202:3306" user="root" password="root" />
</writeHost>
</dataHost>
<!-- 配置db_user的节点主机 -->
<dataHost name="db_userHOST1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="userHost1" url="192.168.204.201:3306" user="root" password="root">
</writeHost>
</dataHost>
<dataHost name="db_userHOST2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="userHost2" url="192.168.204.202:3306" user="root" password="root">
</writeHost>
</dataHost>
</mycat:schema>